Лучше GPT-4o? Представлена Llama 3.1 — крупнейшая в мире ИИ-модель с открытым кодом
Meta* показала семейство языковых моделей Llama 3.1. Флагманский вариант нейросети содержит 405 млрд параметров и во многих тестах обходит лидеров отрасли. Рассказываем о возможностях новинок.
Рекордный датасет и сниженные цены
Для обучения использовались 16 тысяч видеокарт NVIDIA H100 в течение нескольких месяцев. Несмотря на крупные вложения в разработку, Llama 3.1 распространяется с открытым исходным кодом. Это позволяет не только запускать модели локально, но и упрощает их адаптацию под свои нужды. Правда, ресурсоёмкая Llama 405B рассчитана на применение в промышленных условиях. А для широкого круга пользователей до версии 3.1 обновили Llama 8B и 70B. Это компактные аналоги, поддерживаемые обычными компьютерами.
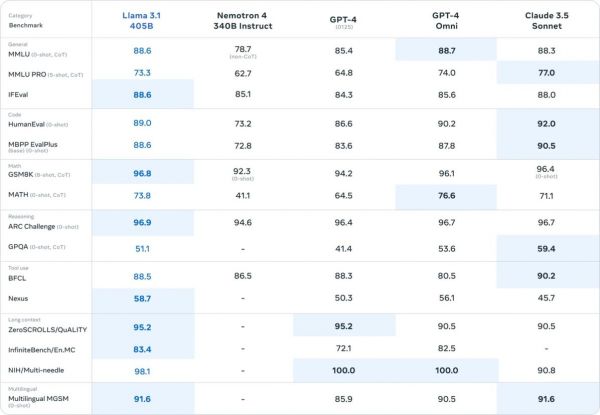
Все версии теперь взаимодействуют с 8 языками, включая английский, французский, немецкий, хинди, итальянский, португальский, испанский и тайский. Контекстное окно составляет 128 000 токенов. Что касается бенчмарков, в ключевых метриках заметно превосходство над прежними лидерами (Claude 3.5 Sonnet и GPT-4o) в пределах двух процентов. В тестах математики (GSM8K и MGSM) топовая Llama демонстрирует 96,8% и 91,6% точности; в ARC Challenge (научные рассуждения) — 96,9%, в Nexus (мультиязычное понимание) — 58,7%.
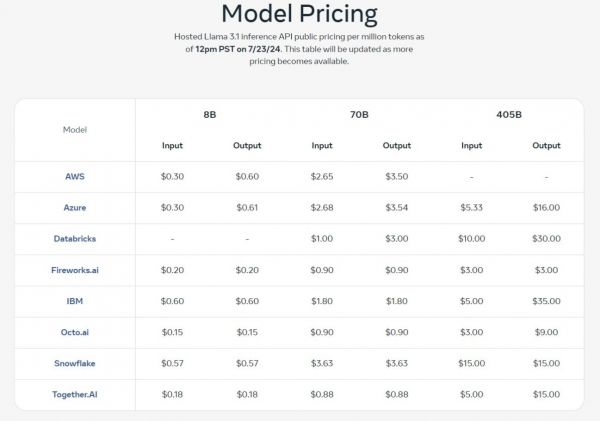
Во всех отношениях подросли и результаты младших моделей (Llama 8B и 70B), если сравнивать с их апрельскими версиями. Прирост достигает от 5 до 30 процентов, в зависимости от сценария. Нейронки распространяют через API разные поставщики облачных услуг. Например, Octo.ai предлагает следующие цены за миллион токенов (примерно 0,75 слова):
-
Llama 8B: вход — $0,15, выход — $0,15;
-
Llama 70B: вход — $0,9, выход — $0,9;
-
Llama 405B: вход — $3, выход — $9.
Дополнительные тесты
Ещё разработчик предоставил данные по человеческим оценкам ответов от разных ИИ. Заявлено, что при сравнении с GPT-4o результаты Llama 3.1 посчитали лучшими в 19,1% случаев, в 29,2% отдали предпочтение OpenAI, а в 51,7% запросов модели оказались равны. Есть и более точные продуктовые бенчмарки, тестирующие множество LLM в корпоративных задачах. Согласно им, самая базовая Llama 8B Instruct пока не продемонстрировала весомых улучшений (скорее всего, требуется более точная настройка для этих сценариев).
Средний вариант 70B показал заметный рывок в качестве, достигнув уровня Gemini Pro 1.5. Также удалось обойти GPT 3.5 и приблизиться к показателям Mistral Large 2. Последняя имеет 123 млрд параметров и требует больше ресурсов, так что здесь Llama отличилась хорошей эффективностью. Наконец, модификация 405B Instruct впервые превзошла уровень одной из версий GPT-4 Turbo (v3/1106) и почти догнала Claude 3 Opus. «Если учитывать размеры и чувствительность к сжатию, её будет использовать меньшее число людей, нежели 70B/8B. Значит, будет меньше тюнов и интересных решений», — отмечает эксперт, проводивший тестирование. Тем не менее среди открытых моделей это лидирующие цифры.
* Деятельность компании Meta Inc. и её продуктов Instagram и Facebook признана в России экстремистской